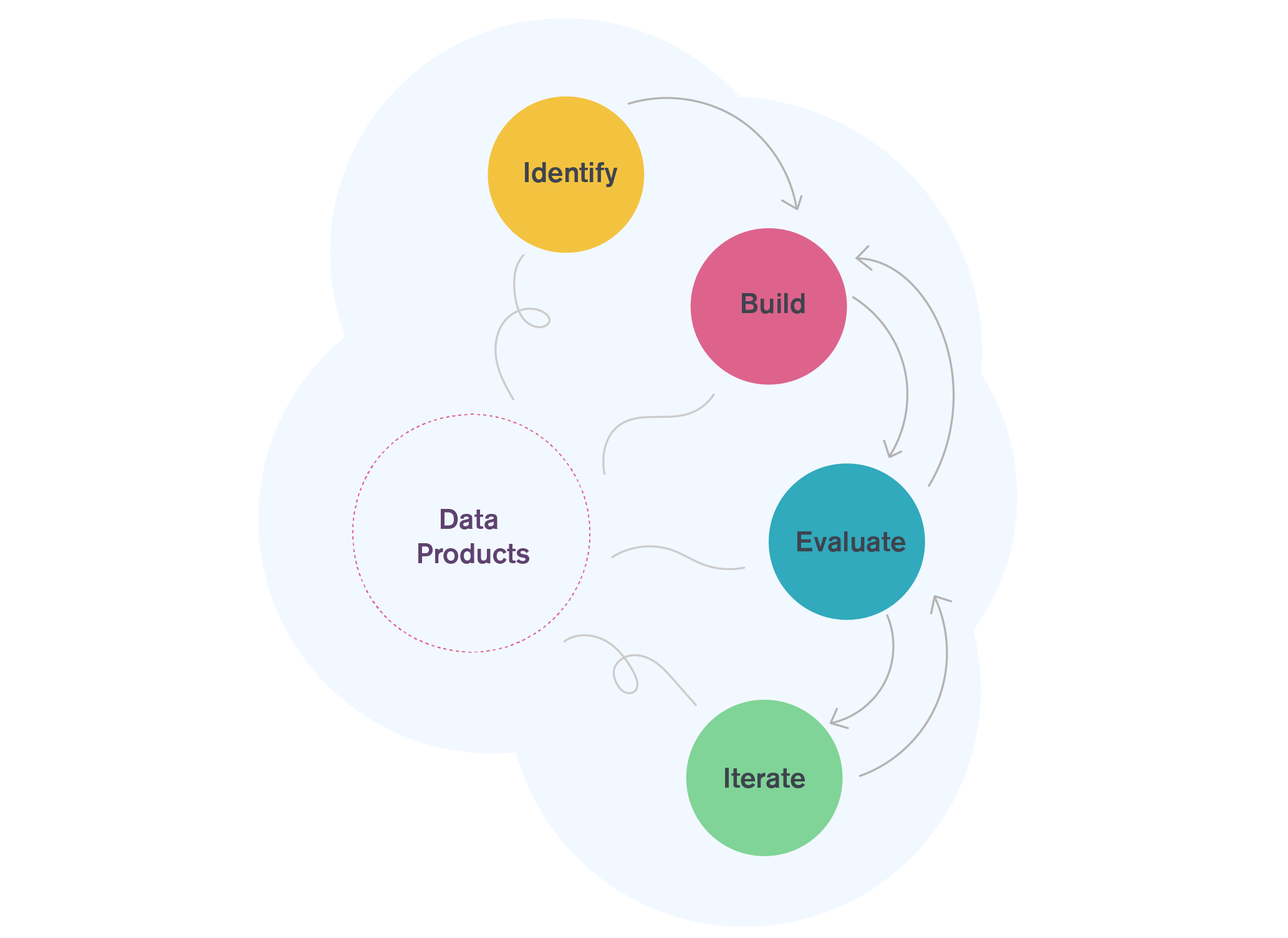
Stage 1: Identify the opportunity, Data products are a team sport
Identifying the best data-product opportunities demands marrying the product-and-business perspective with the tech-and-data perspective. Product managers, user researchers, and business leaders traditionally have the strong intuition and domain expertise to identify key unsolved user and business needs. Meanwhile, data scientists and engineers have a keen eye for identifying feasible data-powered solutions and a strong intuition on what can be scaled and how.
Stage 2: Build the product, De-risk by staging execution
Data products generally require validation both of whether the algorithm works, and of whether users like it. As a result, builders of data products face an inherent tension between how much to invest in the R&D upfront and how quickly to get the application out to validate that it solves a core need.
Teams that over-invest in technical validation before validating product-market fit risk wasted R&D efforts pointed at the wrong problem or solution. Conversely, teams that over-invest in validating user demand without sufficient R&D can end up presenting users with an underpowered prototype, and so risk a false negative. Teams on this end of the spectrum may release an MVP powered by a weak model; if users don't respond well, it may be that with stronger R&D powering the application the result would have been different.
While there's no silver bullet for simultaneously validating the tech and the product-market fit, staged execution can help. Starting simple will accelerate both testing and the collection of valuable data. In building out our Skills Graph, for example, we initially launched skills-based search — an application that required only a small subset of the graph, and that generated a wealth of additional training data
Stage 3: Evaluate and iterate, consider future potential when evaluating data product performance.
Evaluating results after a launch to make a go or no-go decision for a data product is not as straightforward as for a simple UI tweak. That's because the data product may improve substantially as you collect more data, and because foundational data products may enable much more functionality over time. Before canning a data product that does not look like an obvious win, ask your data scientists to quantify answers to a few important questions. For example, at what rate is the product improving organically from data collection? How much low-hanging fruit is there for algorithmic improvements? What kinds of applications will this unlock in the future? Depending on the answers to these questions, a product with uninspiring metrics today might deserve to be preserved.